千年古縣的新答卷

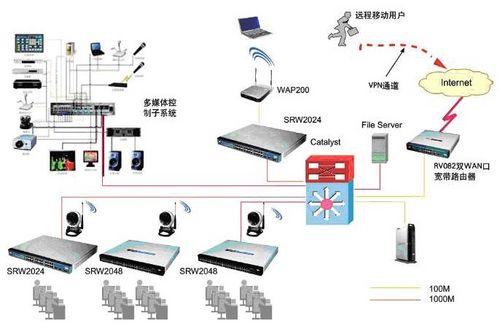
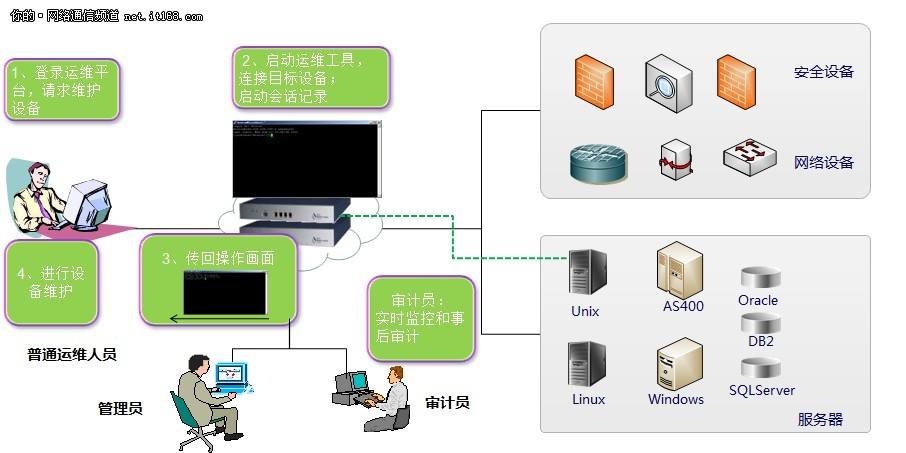
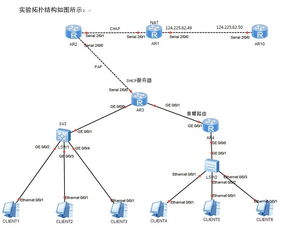
十余輛采訪車沿秦嶺北麓蜿蜒而行,車窗外的初夏藍(lán)田,綠意侵染白鹿原,果園掩映于村落之間。17家主流媒體與網(wǎng)絡(luò)大V組成聯(lián)合采訪團(tuán),深入從前的深度貧困山區(qū)、今日“千萬(wàn)工程”樣板縣藍(lán)田,從產(chǎn)業(yè)富民與數(shù)字賦智兩個(gè)側(cè)面,探尋激活千年古縣的一條“和美鄉(xiāng)村振興路”。\n\n###數(shù)據(jù)化治理實(shí)現(xiàn)農(nóng)村“智慧變身”\n穿過(guò)村口的山桃樹林,采訪團(tuán)來(lái)到?jīng)?zhèn)薛家河村。在最顯眼的位置,一塊長(zhǎng)7米、高3米的木制監(jiān)管展示欄引人駐足。“昨天垃圾分類紅榜戶7家,氣象預(yù)報(bào)今天午后變天,衛(wèi)生所可查遠(yuǎn)程慢病檔案……大家都知道看‘實(shí)時(shí)大板’解疑惑。”駐村“法律明白人”薛毅對(duì)此十分自豪,兩塊簡(jiǎn)單的數(shù)據(jù)大屏與后臺(tái)對(duì)接農(nóng)網(wǎng)、治河分派、農(nóng)業(yè)電商數(shù)據(jù),讓這個(gè)傳統(tǒng)人居新村迅速接入美林綠鎮(zhèn)的數(shù)智防跌跌鏈。村落出口、澗河道支流傳感覆蓋率達(dá)到歷史的100%。“上級(jí)給了7類駐村15年的設(shè)備補(bǔ)貼,‘網(wǎng)絡(luò)管農(nóng)家’絕不是口號(hào)了”,屏幕流光反照田居變化。坐在嶄新的寬大的柏油路凳上,78歲的胡西青怎么也解釋不清鄉(xiāng)槨到6X村標(biāo)為何被群眾一眼發(fā)覺觸網(wǎng)升級(jí),卻會(huì)多聲念叨藍(lán)田寬帶與灌溉支指到家家地。從前的高寒林逆成色蛻盡,數(shù)據(jù)的更適化成抓大的萬(wàn)項(xiàng)凈的始念。這一千萬(wàn)過(guò)程終端帶給我們實(shí)質(zhì)感覺是什么?是一種踏實(shí)的安全——干半天甜地里樂多見的結(jié)具活力。\
最新產(chǎn)品